Konstrukcija empirijske funkcije distribucije. Empirijska funkcija raspodjele, svojstva. Svojstva empirijske funkcije distribucije
Kao što znate, zakon o distribuciji slučajna varijabla može se specificirati na različite načine. Diskretna slučajna varijabla se može specificirati korištenjem distribucijske serije ili integralne funkcije, a kontinuirana slučajna varijabla može se specificirati korištenjem integralne ili diferencijalne funkcije. Razmotrimo selektivne analoge ove dvije funkcije.
Neka postoji uzorak skupa vrijednosti neke slučajne varijable volumena  i svakoj varijanti iz ovog skupa je dodeljena njena frekvencija. Pustite dalje
i svakoj varijanti iz ovog skupa je dodeljena njena frekvencija. Pustite dalje  - neke pravi broj, a
- neke pravi broj, a  je broj vrijednosti uzorka slučajne varijable
je broj vrijednosti uzorka slučajne varijable  , manji
, manji  .Onda broj
.Onda broj  je učestalost vrijednosti uočenih u uzorku X, manji
je učestalost vrijednosti uočenih u uzorku X, manji  ,
one. učestalost pojavljivanja događaja
,
one. učestalost pojavljivanja događaja 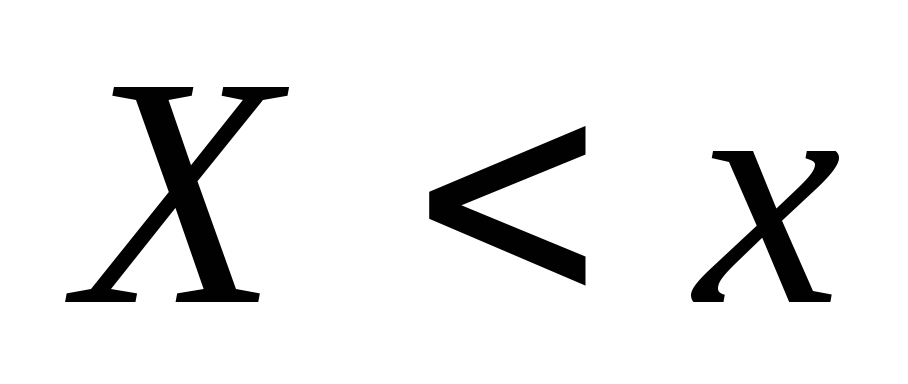 . Kada se promeni x u opštem slučaju, vrednost će se takođe promeniti
. Kada se promeni x u opštem slučaju, vrednost će se takođe promeniti  . To znači da je relativna frekvencija
. To znači da je relativna frekvencija  je funkcija argumenta
je funkcija argumenta  . A budući da se ova funkcija nalazi prema uzorku podataka dobivenih kao rezultat eksperimenata, naziva se uzorak ili empirijski.
. A budući da se ova funkcija nalazi prema uzorku podataka dobivenih kao rezultat eksperimenata, naziva se uzorak ili empirijski.
Definicija 10.15. Empirijska funkcija distribucije(funkcija distribucije uzorkovanja) naziva se funkcija  , definiranje za svaku vrijednost x relativna učestalost događaja
, definiranje za svaku vrijednost x relativna učestalost događaja  .
.
 (10.19)
(10.19)
Za razliku od empirijske funkcije distribucije uzorka, funkcija distribucije F(x)
stanovništva pozvao teorijska funkcija distribucije. Razlika između njih je u teorijskoj funkciji F(x)
određuje vjerovatnoću događaja 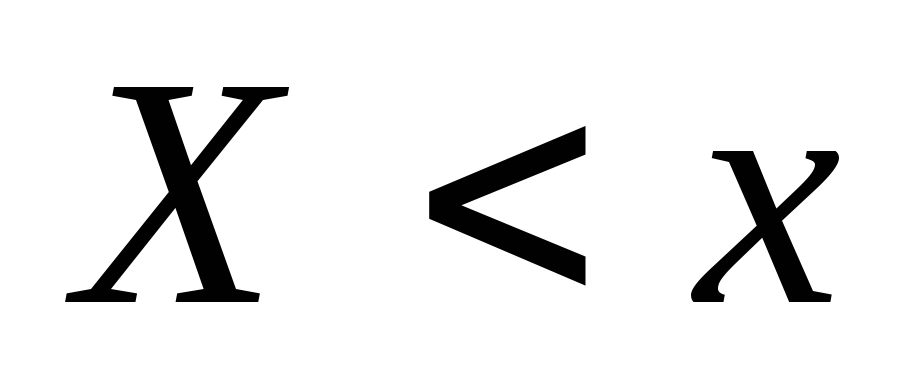 , a empirijski je relativna učestalost istog događaja. Iz Bernoullijeve teoreme slijedi
, a empirijski je relativna učestalost istog događaja. Iz Bernoullijeve teoreme slijedi
 ,
,
 (10.20)
(10.20)
one. na slobodi  vjerovatnoća
vjerovatnoća  i relativnu frekvenciju događaja
i relativnu frekvenciju događaja  , tj.
, tj.  malo različiti jedno od drugog. Ovo već implicira svrsishodnost korištenja empirijske funkcije distribucije uzorka za približan prikaz teorijske (integralne) funkcije raspodjele opće populacije.
malo različiti jedno od drugog. Ovo već implicira svrsishodnost korištenja empirijske funkcije distribucije uzorka za približan prikaz teorijske (integralne) funkcije raspodjele opće populacije.
Funkcija  i
i  imaju ista svojstva. Ovo dolazi iz definicije funkcije.
imaju ista svojstva. Ovo dolazi iz definicije funkcije. 
Svojstva  :
:

Primjer 10.4. Konstruirajte empirijsku funkciju za datu distribuciju uzorka:
|
Opcije | |||
|
Frekvencije |


Rješenje: Pronađite veličinu uzorka n=
12+18+30=60. Najmanja opcija  , Shodno tome,
, Shodno tome,  at
at 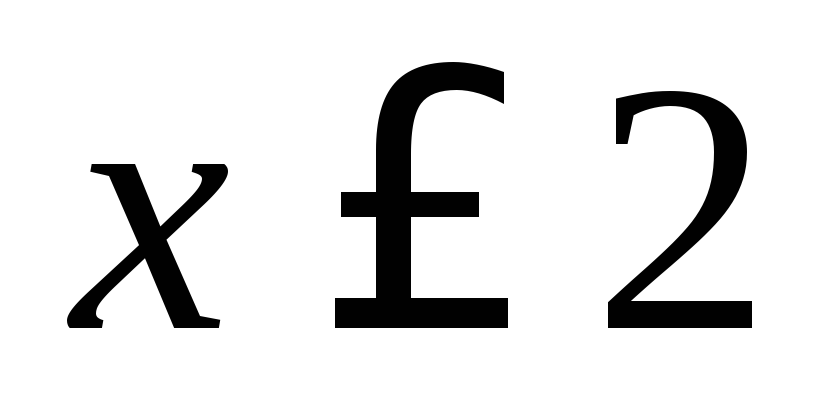 . Značenje
. Značenje  , naime
, naime  posmatrano 12 puta, dakle:
posmatrano 12 puta, dakle:
 =
= at
at  .
.
Značenje x<
10, naime  i
i  posmatrano 12+18=30 puta, dakle,
posmatrano 12+18=30 puta, dakle,  =
=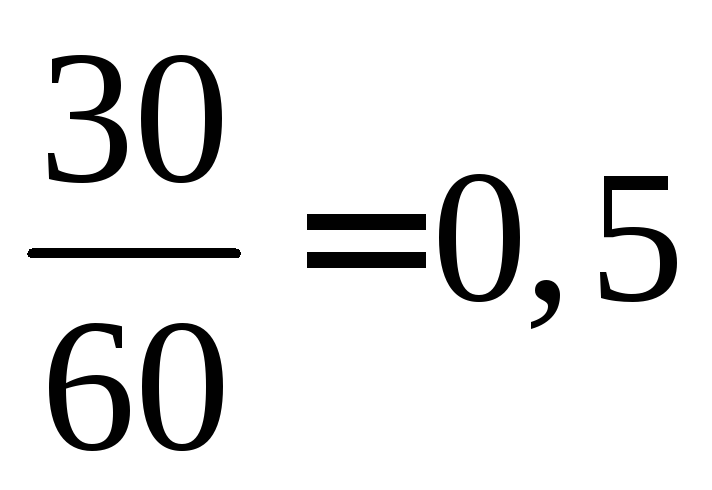 at
at  . At
. At 
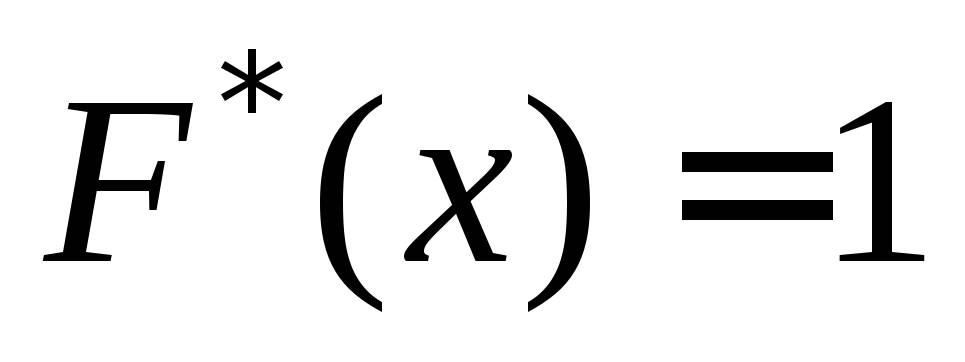 .
.
Željena empirijska funkcija distribucije:
 =
=
Raspored  prikazano na sl. 10.2
prikazano na sl. 10.2
R  je. 10.2
je. 10.2
test pitanja
1. Koji su glavni problemi koje rješava matematička statistika? 2. Opća i uzorkovana populacija? 3. Definirajte veličinu uzorka. 4. Koji se uzorci nazivaju reprezentativnim? 5. Greške u reprezentativnosti. 6. Glavne metode uzorkovanja. 7. Koncepti frekvencije, relativne frekvencije. 8. Koncept statističke serije. 9. Zapišite Sturgesovu formulu. 10. Formulirajte koncepte raspona uzorka, medijana i moda. 11. Frekvencije poligona, histogram. 12. Koncept bodovne procjene populacije uzorka. 13. Pristrasna i nepristrasna procjena bodova. 14. Formulirajte koncept srednje vrijednosti uzorka. 15. Formulirajte koncept varijanse uzorka. 16. Formulirajte koncept standardne devijacije uzorka. 17. Formulirajte koncept koeficijenta varijacije uzorka. 18. Formulirajte koncept uzorka geometrijske sredine.
Predavanje 13
Neka se zna statistička distribucija frekvencije kvantitativno svojstvo X. Označiti sa brojem opažanja u kojima je uočena vrijednost karakteristike manja od x i sa n - ukupan broj zapažanja. Očigledno, relativna učestalost događaja X< x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Empirijska funkcija distribucije(funkcija distribucije uzorkovanja) je funkcija koja za svaku vrijednost x određuje relativnu frekvenciju događaja X< x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
Za razliku od empirijske funkcije distribucije uzorka, naziva se funkcija raspodjele populacije teorijska funkcija raspodjele. Razlika između ovih funkcija je u tome što teorijska funkcija definira vjerovatnoća događaji X< x, тогда как эмпирическая – relativna frekvencija isti događaj.
Kako n raste, relativna frekvencija događaja X< x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Svojstva empirijske funkcije distribucije:
1) Vrijednosti empirijske funkcije pripadaju segmentu
2) - neopadajuća funkcija
3) Ako - najmanja opcija, onda = 0 na , ako - najveća opcija, onda =1 na .
empirijska funkcija Distribucija uzorka služi za procjenu teorijske funkcije distribucije populacije.
Primjer. Izgradimo empirijsku funkciju prema distribuciji uzorka:
| Opcije | |||
| Frekvencije |
Nađimo veličinu uzorka: 12+18+30=60. Najmanja opcija je 2, dakle =0 za x £ 2. Vrijednost x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x>10. Dakle, željena empirijska funkcija ima oblik:
Najvažnija svojstva statističkih procjena
Neka se zahtijeva proučavanje nekog kvantitativnog atributa opće populacije. Pretpostavimo da je iz teorijskih razmatranja to bilo moguće utvrditi koji distribucija ima atribut i potrebno je procijeniti parametre po kojima je određena. Na primjer, ako je ispitivana osobina normalno raspoređena u općoj populaciji, tada je potrebno procijeniti očekivanu vrijednost i standardna devijacija; ako atribut ima Poissonovu distribuciju, tada je potrebno procijeniti parametar l.
Obično su dostupni samo uzorci podataka, kao što su vrijednosti osobina iz n nezavisnih opservacija. Uzimajući u obzir nezavisne slučajne varijable, možemo to reći pronaći statističku procjenu nepoznatog parametra teorijske distribucije znači pronaći funkciju promatranih slučajnih varijabli koja daje približnu vrijednost procijenjenog parametra. Na primjer, za procjenu matematičkog očekivanja normalna distribucija ulogu funkcije obavlja aritmetička sredina
Da bi statističke procjene dale ispravne aproksimacije procijenjenih parametara, one moraju zadovoljiti određene zahtjeve, među kojima su najvažniji zahtjevi nepristrasnost i solventnost procjene.
Neka - statistička evaluacija nepoznati parametar teorijske distribucije. Neka se procjena nađe na osnovu uzorka veličine n. Ponovimo eksperiment, tj. izdvajamo iz opšte populacije drugi uzorak iste veličine i, na osnovu njegovih podataka, dobijamo drugačiju procenu od . Ponavljajući eksperiment mnogo puta, dobijamo različite brojeve. Rezultat se može posmatrati kao slučajna varijabla, a brojevi kao njene moguće vrijednosti.
Ako procjena daje aproksimaciju u izobilju, tj. svaki broj je veći od prave vrijednosti, tada je, kao posljedica toga, matematičko očekivanje (srednja vrijednost) slučajne varijable veće od:. Slično, ako procjenjuje sa nedostatkom, zatim .
Dakle, korištenje statističke procjene, čije matematičko očekivanje nije jednako procijenjenom parametru, dovelo bi do sistematskih (jednoznačnih) grešaka. Ako je, naprotiv, , onda to garantuje protiv sistematskih grešaka.
nepristrasan naziva se statistička procjena, čije je matematičko očekivanje jednako procijenjenom parametru za bilo koju veličinu uzorka.
Displaced naziva se procjena koja ne zadovoljava ovaj uslov.
Nepristranost procjene još ne garantuje dobru aproksimaciju za procijenjeni parametar, jer moguće vrijednosti mogu biti veoma raštrkano oko svoje srednje vrednosti, tj. varijansa može biti značajna. U ovom slučaju, procjena pronađena iz podataka jednog uzorka, na primjer, može se pokazati značajno udaljenom od prosječne vrijednosti, a time i od samog procijenjenog parametra.
efikasan naziva se statistička procjena koja, za datu veličinu uzorka n, ima najmanju moguću varijaciju .
Kada se razmatraju uzorci velikog volumena, potrebne su statističke procjene solventnost .
Bogati naziva se statistička procjena, koja, kao n®¥, teži vjerovatnoći procijenjenom parametru. Na primjer, ako varijansa nepristrasnog estimatora teži nuli kao n®¥, onda se i takav estimator ispostavi da je konzistentan.
Određivanje empirijske funkcije distribucije
Neka je $X$ slučajna varijabla. $F(x)$ - funkcija distribucije date slučajne varijable. Provešćemo $n$ eksperimente na datoj slučajnoj promenljivoj pod istim nezavisnim uslovima. U ovom slučaju dobijamo niz vrijednosti $x_1,\ x_2\ $, ... ,$\ x_n$, koji se naziva uzorak.
Definicija 1
Svaka vrijednost $x_i$ ($i=1,2\ $, ... ,$ \ n$) naziva se varijanta.
Jedna od procjena teorijske funkcije raspodjele je empirijska funkcija raspodjele.
Definicija 3
Empirijska funkcija distribucije $F_n(x)$ je funkcija koja za svaku vrijednost $x$ određuje relativnu frekvenciju događaja $X \
gdje je $n_x$ broj opcija manji od $x$, $n$ je veličina uzorka.
Razlika između empirijske funkcije i teorijske je u tome što teorijska funkcija određuje vjerovatnoću događaja $X
Svojstva empirijske funkcije distribucije
Razmotrimo sada nekoliko osnovnih svojstava funkcije distribucije.
Opseg funkcije $F_n\left(x\right)$ je segment $$.
$F_n\left(x\right)$ je neopadajuća funkcija.
$F_n\left(x\right)$ je lijeva kontinuirana funkcija.
$F_n\left(x\right)$ je konstantna funkcija po komadima i raste samo u tačkama vrijednosti slučajne varijable $X$
Neka je $X_1$ najmanja, a $X_n$ najveća varijanta. Tada je $F_n\left(x\right)=0$ za $(x\le X)_1$ i $F_n\left(x\right)=1$ za $x\ge X_n$.
Hajde da uvedemo teoremu koja povezuje teorijske i empirijske funkcije.
Teorema 1
Neka je $F_n\left(x\right)$ empirijska funkcija raspodjele i $F\left(x\right)$ teorijska funkcija raspodjele općeg uzorka. Tada vrijedi jednakost:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Primjeri problema za pronalaženje empirijske funkcije raspodjele
Primjer 1
Neka distribucija uzorka ima sljedeće podatke, zabilježene pomoću tabele:
Slika 1.
Pronađite veličinu uzorka, sastavite empirijsku funkciju distribucije i nacrtajte je.
Veličina uzorka: $n=5+10+15+20=50$.
Prema svojstvu 5, imamo da je za $x\le 1$ $F_n\left(x\right)=0$, a za $x>4$ $F_n\left(x\right)=1$.
$x vrijednost
$x vrijednost
$x vrijednost
Dakle, dobijamo:
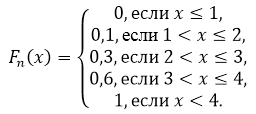
Slika 2.

Slika 3
Primjer 2
Iz gradova centralnog dela Rusije nasumično je odabrano 20 gradova za koje su dobijeni sledeći podaci o cenama prevoza u javnom prevozu: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15 , 14, 15, 13 , 13, 12, 12, 15, 14, 14.
Sastavite empirijsku funkciju distribucije ovog uzorka i izgradite njegov graf.
Vrijednosti uzorka pišemo uzlaznim redoslijedom i izračunavamo učestalost svake vrijednosti. Dobijamo sledeću tabelu:
Slika 4
Veličina uzorka: $n=20$.
Prema svojstvu 5, imamo da je za $x\le 12$ $F_n\left(x\right)=0$, a za $x>15$ $F_n\left(x\right)=1$.
$x vrijednost
$x vrijednost
$x vrijednost
Dakle, dobijamo:
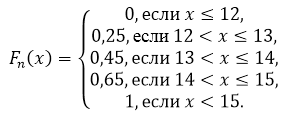
Slika 5
Nacrtajmo empirijsku distribuciju:

Slika 6
Originalnost: $92,12\%$.
Naučite šta je empirijska formula. U hemiji, ESP je najjednostavniji način da se opiše jedinjenje – u suštini, to je lista elemenata koji čine jedinjenje s obzirom na njihov procenat. Treba napomenuti da ova jednostavna formula ne opisuje red atoma u jedinjenju, jednostavno ukazuje od kojih se elemenata sastoji. Na primjer:
- Jedinjenje koje se sastoji od 40,92% ugljika; 4,58% vodonika i 54,5% kiseonika, imaće empirijsku formulu C 3 H 4 O 3 (primer kako pronaći ESP ovog jedinjenja biće reči u drugom delu).
Naučite pojam "procentualni sastav"."Procentni sastav" se odnosi na postotak svakog pojedinačnog atoma u cijelom spoju koji se razmatra. Da biste pronašli empirijsku formulu jedinjenja, potrebno je znati procentualni sastav jedinjenja. Ako pronađete empirijsku formulu kao zadaća, tada će se vjerovatno dati kamata.
- Da nađem procenat hemijsko jedinjenje u laboratoriju se podvrgava nekim fizičkim eksperimentima, a zatim kvantitativnoj analizi. Ako niste u laboratoriji, ne morate raditi ove eksperimente.
Imajte na umu da ćete morati da se nosite sa gram atomima. Gram atom je određena količina supstance čija je masa jednaka njenoj atomskoj masi. Da biste pronašli gram atom, trebate koristiti sljedeću jednačinu: Postotak elementa u spoju podijeljen je s atomskom masom elementa.
- Recimo, na primjer, da imamo spoj koji sadrži 40,92% ugljika. Atomska masa ugljenik je 12, tako da bi naša jednadžba bila 40,92 / 12 = 3,41.
Znati kako pronaći atomski omjer. Kada radite sa jedinjenjem, na kraju ćete dobiti više od jednog atoma grama. Nakon što pronađete sve gram atoma vašeg spoja, pogledajte ih. Da biste pronašli atomski omjer, morat ćete odabrati najmanju vrijednost gram-atoma koju ste izračunali. Tada će biti potrebno podijeliti sve gram-atome na najmanji gram-atom. Na primjer:
- Pretpostavimo da radite sa jedinjenjem koje sadrži tri grama atoma: 1,5; 2 i 2.5. Najmanji od ovih brojeva je 1,5. Stoga, da biste pronašli omjer atoma, morate podijeliti sve brojeve sa 1,5 i staviti znak omjera između njih : .
- 1,5 / 1,5 = 1, 2 / 1,5 = 1,33. 2,5 / 1,5 = 1,66. Dakle, odnos atoma je 1: 1,33: 1,66 .
Naučite kako pretvoriti vrijednosti atomskog omjera u cijele brojeve. Kada pišete empirijsku formulu, morate koristiti cijele brojeve. To znači da ne možete koristiti brojeve poput 1.33. Nakon što pronađete omjer atoma, trebate pretvoriti razlomke (poput 1,33) u cijele brojeve (kao 3). Da biste to učinili, morate pronaći cijeli broj, množenjem svakog broja atomskog omjera kojim dobijate cijele brojeve. Na primjer:
- Pokušajte 2. Pomnožite brojeve atomskog omjera (1, 1,33 i 1,66) sa 2. Dobićete 2, 2,66 i 3,32. Oni nisu cijeli brojevi, tako da 2 nije prikladno.
- Pokušajte 3. Ako pomnožite 1, 1,33 i 1,66 sa 3, dobićete 3, 4, odnosno 5. Dakle, atomski omjer cijelih brojeva ima oblik 3: 4: 5 .
Određivanje empirijske funkcije distribucije
Neka je $X$ slučajna varijabla. $F(x)$ - funkcija distribucije date slučajne varijable. Provešćemo $n$ eksperimente na datoj slučajnoj promenljivoj pod istim nezavisnim uslovima. U ovom slučaju dobijamo niz vrijednosti $x_1,\ x_2\ $, ... ,$\ x_n$, koji se naziva uzorak.
Definicija 1
Svaka vrijednost $x_i$ ($i=1,2\ $, ... ,$ \ n$) naziva se varijanta.
Jedna od procjena teorijske funkcije raspodjele je empirijska funkcija raspodjele.
Definicija 3
Empirijska funkcija distribucije $F_n(x)$ je funkcija koja za svaku vrijednost $x$ određuje relativnu frekvenciju događaja $X \
gdje je $n_x$ broj opcija manji od $x$, $n$ je veličina uzorka.
Razlika između empirijske funkcije i teorijske je u tome što teorijska funkcija određuje vjerovatnoću događaja $X
Svojstva empirijske funkcije distribucije
Razmotrimo sada nekoliko osnovnih svojstava funkcije distribucije.
Opseg funkcije $F_n\left(x\right)$ je segment $$.
$F_n\left(x\right)$ je neopadajuća funkcija.
$F_n\left(x\right)$ je lijeva kontinuirana funkcija.
$F_n\left(x\right)$ je konstantna funkcija po komadima i raste samo u tačkama vrijednosti slučajne varijable $X$
Neka je $X_1$ najmanja, a $X_n$ najveća varijanta. Tada je $F_n\left(x\right)=0$ za $(x\le X)_1$ i $F_n\left(x\right)=1$ za $x\ge X_n$.
Hajde da uvedemo teoremu koja povezuje teorijske i empirijske funkcije.
Teorema 1
Neka je $F_n\left(x\right)$ empirijska funkcija raspodjele i $F\left(x\right)$ teorijska funkcija raspodjele općeg uzorka. Tada vrijedi jednakost:
\[(\mathop(lim)_(n\to \infty ) (|F)_n\left(x\right)-F\left(x\right)|=0\ )\]
Primjeri problema za pronalaženje empirijske funkcije raspodjele
Primjer 1
Neka distribucija uzorka ima sljedeće podatke, zabilježene pomoću tabele:
Slika 1.
Pronađite veličinu uzorka, sastavite empirijsku funkciju distribucije i nacrtajte je.
Veličina uzorka: $n=5+10+15+20=50$.
Prema svojstvu 5, imamo da je za $x\le 1$ $F_n\left(x\right)=0$, a za $x>4$ $F_n\left(x\right)=1$.
$x vrijednost
$x vrijednost
$x vrijednost
Dakle, dobijamo:
Slika 2.
Slika 3
Primjer 2
Iz gradova centralnog dela Rusije nasumično je odabrano 20 gradova za koje su dobijeni sledeći podaci o cenama prevoza u javnom prevozu: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15 , 14, 15, 13 , 13, 12, 12, 15, 14, 14.
Sastavite empirijsku funkciju distribucije ovog uzorka i izgradite njegov graf.
Vrijednosti uzorka pišemo uzlaznim redoslijedom i izračunavamo učestalost svake vrijednosti. Dobijamo sledeću tabelu:
Slika 4
Veličina uzorka: $n=20$.
Prema svojstvu 5, imamo da je za $x\le 12$ $F_n\left(x\right)=0$, a za $x>15$ $F_n\left(x\right)=1$.
$x vrijednost
$x vrijednost
$x vrijednost
Dakle, dobijamo:
Slika 5
Nacrtajmo empirijsku distribuciju:
Slika 6
Originalnost: $92,12\%$.





