The law of large numbers in theory. The law of large numbers. Limit theorems. Law of large numbers in Bernoulli form
Don't lose. Subscribe and receive a link to the article in your email.
Interacting daily in work or study with numbers and numbers, many of us do not even suspect that there is a very interesting law big numbers used, for example, in statistics, economics, and even psychological and pedagogical research. It refers to the theory of probability and says that the arithmetic mean of any large sample from a fixed distribution is close to the mathematical expectation of this distribution.
You probably noticed that it is not easy to understand the essence of this law, especially for those who are not particularly friendly with mathematics. Based on this, we would like to talk about it plain language(as far as possible, of course), so that everyone can at least roughly understand for themselves what it is. This knowledge will help you better understand some mathematical patterns, become more erudite and positively influence.
Concepts of the law of large numbers and its interpretation
In addition to the above definition of the law of large numbers in probability theory, we can give its economic interpretation. In this case, it is the principle that the frequency of a particular type of financial loss can be predicted with a high degree of certainty when there is high level losses of such types in general.
In addition, depending on the level of convergence of features, we can distinguish the weak and strengthened laws of large numbers. About the weak we are talking, when convergence exists in probability, and about enhanced - when convergence exists in almost everything.
If we interpret it a little differently, then we should say this: it is always possible to find such a finite number of trials, where, with any preprogrammed probability less than one, the relative frequency of occurrence of some event will differ very little from its probability.
Thus, the general essence of the law of large numbers can be expressed as follows: the result of the complex action of a large number of identical and independent random factors will be such a result that does not depend on chance. And speaking even more simply, then in the law of large numbers, the quantitative laws of mass phenomena will clearly manifest themselves only when there are a large number of them (which is why the law of large numbers is called the law).
From this we can conclude that the essence of the law lies in the fact that in the numbers that are obtained by mass observation, there are some correctness, which cannot be detected in a small number of facts.
The essence of the law of large numbers and its examples
The law of large numbers expresses the most general patterns of the accidental and the necessary. When random deviations "extinguish" each other, the averages determined for the same structure take on the form of typical ones. They reflect the operation of essential and permanent facts under the specific conditions of time and place.
Regularities defined by the law of large numbers are strong only when they represent mass tendencies, and they cannot be laws for individual cases. Thus, the principle mathematical statistics, which says that the complex action of a number of random factors can cause a non-random result. And the most striking example of the operation of this principle is the convergence of the frequency of occurrence of a random event and its probability when the number of trials increases.
Let's remember the usual coin toss. Theoretically, heads and tails can fall out with the same probability. This means that if, for example, a coin is tossed 10 times, 5 of them should come up heads and 5 should come up heads. But everyone knows that this almost never happens, because the ratio of the frequency of heads and tails can be 4 to 6, and 9 to 1, and 2 to 8, etc. However, with an increase in the number of coin tosses, for example, up to 100, the probability that heads or tails will fall out reaches 50%. If, theoretically, an infinite number of such experiments are carried out, the probability of a coin falling out on both sides will always tend to 50%.
How exactly the coin will fall is influenced by a huge number of random factors. This is the position of the coin in the palm of your hand, and the force with which the throw is made, and the height of the fall, and its speed, etc. But if there are many experiments, regardless of how the factors act, it can always be argued that the practical probability is close to the theoretical probability.
And here is another example that will help to understand the essence of the law of large numbers: suppose we need to estimate the level of earnings of people in a certain region. If we consider 10 observations, where 9 people receive 20 thousand rubles, and 1 person - 500 thousand rubles, the arithmetic mean will be 68 thousand rubles, which, of course, is unlikely. But if we take into account 100 observations, where 99 people receive 20 thousand rubles, and 1 person - 500 thousand rubles, then when calculating the arithmetic mean, we get 24.8 thousand rubles, which is already closer to the real state of affairs. By increasing the number of observations, we will force the average value to tend to the true value.
It is for this reason that in order to apply the law of large numbers, it is first necessary to collect statistical material in order to obtain truthful results by studying big number observations. That is why it is convenient to use this law, again, in statistics or social economics.
Summing up
The significance of the fact that the law of large numbers works is difficult to overestimate for any field. scientific knowledge, and especially for scientific developments in the field of the theory of statistics and methods of statistical knowledge. The action of the law is also of great importance for the objects under study themselves with their mass regularities. Almost all methods of statistical observation are based on the law of large numbers and the principle of mathematical statistics.
But, even without taking into account science and statistics as such, we can safely conclude that the law of large numbers is not just a phenomenon from the field of probability theory, but a phenomenon that we encounter almost every day in our lives.
We hope that now the essence of the law of large numbers has become more clear to you, and you can easily and simply explain it to someone else. And if the topic of mathematics and probability theory is of interest to you in principle, then we recommend reading about and. Also get acquainted with and. And, of course, pay attention to ours, because after passing it, you will not only master new thinking techniques, but also improve your cognitive abilities in general, including mathematical ones.
LARGE NUMBERS LAW
a general principle, by virtue of which the combination of random factors leads, under certain very general conditions, to a result almost independent of chance. The convergence of the frequency of occurrence of a random event with its probability with an increase in the number of trials (noted first, apparently, in gambling) can serve as the first example of the operation of this principle.
At the turn of the 17th and 18th centuries. J. Bernoulli proved a theorem stating that in a sequence of independent trials, in each of which the occurrence of a certain event A has the same value, the relation is true:
for any - the number of occurrences of the event in the first trials, - the frequency of occurrences. This Bernoulli theorem was extended by S. Poisson to the case of a sequence of independent trials, where the probability of the occurrence of an event A may depend on the trial number. Let this probability for the kth trial be equal and let
![]()
Then Poisson theorem States that
for any The first rigor of this theorem was given by PL Chebyshev (1846), whose method is completely different from Poisson's method and is based on certain extremal considerations; S. Poisson derived (2) from an approximate formula for the specified probability, based on the use of the Gauss law and at that time still not strictly substantiated. S. Poisson also first encountered the term "law of large numbers", which he called his generalization of Bernoulli's theorem.
A natural further generalization of the Bernoulli and Poisson theorems arises if we note that random variables can be represented as a sum
independent random variables, where if A appears in A-m test, and
- otherwise. At the same time, mathematical expectation (coinciding with the arithmetic mean of mathematical expectations ) is equal to p for the Bernoulli case and for the Poisson case. In other words, in both cases, the deviation of the arithmetic mean is considered X k from the arithmetic mean of their mathematical. expectations.
In the work of P. L. Chebyshev "On average values" (1867), it was established that for independent random variables the relation
(for any ) is true under very general assumptions. P. L. Chebyshev assumed that the mathematical. expectations are all bounded by the same constant, although it is clear from his proof that it suffices to require that the variances be bounded
or even demands
Thus, P. L. Chebyshev showed the possibility of a broad generalization of Bernoulli's theorem. A. A. Markov noted the possibility of further generalizations and suggested using the name B. h. to the entire set of generalizations of Bernoulli's theorem [and, in particular, to (3)]. Chebyshev's method is based on the exact establishment of the general properties of mathematical. expectations and on the use of the so-called. Chebyshev inequalities[for probability (3) it gives an estimate of the form
![]()
this boundary can be replaced by a more accurate one, of course, with more significant restrictions, see Fig. Bernstein inequality].
Subsequent evidence of various forms of B. h. to some extent, they are a development of the Chebyshev method. Applying the appropriate "reduction" of random variables (replacing them with auxiliary variables, namely: , if where are some constants), A. A. Markov extended the B. ch. for cases where the variances of the terms do not exist. For example, he showed that (3) holds if for some constants ![]() and everyone and
and everyone and
The phenomenon of stabilization of the frequency of occurrence of random events, discovered on a large and varied material, at first did not have any justification and was perceived as a purely empirical fact. The first theoretical result in this area was the famous Bernoulli theorem published in 1713, which laid the foundation for the laws of large numbers.
Bernoulli's theorem in its content is a limit theorem, i.e., a statement of asymptotic meaning, saying what will happen to the probabilistic parameters with a large number of observations. The progenitor of all modern numerous statements of this type is precisely Bernoulli's theorem.
Today it seems that the mathematical law of large numbers is a reflection of some common property many real processes.
Having a desire to give the law of large numbers as much scope as possible, corresponding to the far from exhausted potential possibilities of applying this law, one of the greatest mathematicians of our century A. N. Kolmogorov formulated its essence as follows: the law of large numbers is “a general principle, by virtue of which the cumulative the action of a large number of random factors leads to a result almost independent of chance.
Thus, the law of large numbers has, as it were, two interpretations. One is mathematical, associated with specific mathematical models, formulations, theories, and the second is more general, going beyond this framework. The second interpretation is associated with the phenomenon of formation, often noted in practice, of a directed action to one degree or another against the background of a large number of hidden or visible acting factors that do not have such continuity outwardly. Examples related to the second interpretation are pricing in the free market, the formation of public opinion on a particular issue.
Having noted this general interpretation of the law of large numbers, let us turn to the specific mathematical formulations of this law.
As we said above, the first and fundamentally most important for the theory of probability is Bernoulli's theorem. The content of this mathematical fact, which reflects one of the most important regularities of the surrounding world, is reduced to the following.
Consider a sequence of unrelated (i.e., independent) tests, the conditions for which are reproduced invariably from test to test. The result of each test is the appearance or non-appearance of the event of interest to us. BUT.
This procedure (Bernoulli scheme) can obviously be considered typical for many practical areas: "boy - girl" in the sequence of newborns, daily meteorological observations ("it rained - it was not"), control of the flow of manufactured products ("normal - defective") etc.
Frequency of occurrence of the event BUT at P trials ( t A -
event frequency BUT in P tests) has with growth P tendency to stabilize its value, this is an empirical fact.
Bernoulli's theorem. Let us choose any arbitrarily small positive number e. Then
We emphasize that the mathematical fact established by Bernoulli in a certain mathematical model(in the Bernoulli scheme) should not be confused with the empirically established regularity of frequency stability. Bernoulli was not satisfied only with the statement of formula (9.1), but, taking into account the needs of practice, he gave an estimate of the inequality present in this formula. We will return to this interpretation below.
Bernoulli's law of large numbers has been the subject of research by a large number of mathematicians who have sought to refine it. One such refinement was obtained by the English mathematician Moivre and is currently called the Moivre-Laplace theorem. In the Bernoulli scheme, consider the sequence of normalized quantities:
Integral theorem of Moivre - Laplace. Pick any two numbers X ( and x 2 . In this case, x, x 7, then when P -» °°
If on the right side of formula (9.3) the variable x x tend to infinity, then the resulting limit, which depends only on x 2 (in this case, the index 2 can be removed), will be a distribution function, it is called standard normal distribution, or Gauss law.
The right side of formula (9.3) is equal to y = F(x 2) - F(x x). F(x2)-> 1 at x 2-> °° and F(x,) -> 0 for x, -> By choosing a sufficiently large
X] > 0 and sufficiently large in absolute value X] n we obtain the inequality:
Taking into account formula (9.2), we can extract practically reliable estimates:
If the reliability of y = 0.95 (i.e., the error probability of 0.05) may seem insufficient to someone, you can “play it safe” and build a slightly wider confidence interval using the three sigma rule mentioned above:
This interval corresponds to a very high level of confidence y = 0.997 (see tables normal distribution).
Consider the example of tossing a coin. Let's toss a coin n = 100 times. Can it happen that the frequency R will be very different from the probability R= 0.5 (assuming the symmetry of the coin), for example, will it be equal to zero? To do this, it is necessary that the coat of arms does not fall out even once. Such an event is theoretically possible, but we have already calculated such probabilities, for this event it will be equal to  This value
This value
is extremely small, its order is a number with 30 decimal places. An event with such a probability can safely be considered practically impossible. What deviations of the frequency from the probability with a large number of experiments are practically possible? Using the Moivre-Laplace theorem, we answer this question as follows: with probability at= 0.95 coat of arms frequency R fits into the confidence interval:
If the error of 0.05 seems not small, it is necessary to increase the number of experiments (tossing a coin). With an increase P the width of the confidence interval decreases (unfortunately, not as fast as we would like, but inversely proportional to -Jn). For example, when P= 10 000 we get that R lies in the confidence interval with the confidence probability at= 0.95: 0.5 ± 0.01.
Thus, we have dealt quantitatively with the question of the approximation of frequency to probability.
Now let's find the probability of an event from its frequency and estimate the error of this approximation.
Let us make a large number of experiments P(tossed a coin), found the frequency of the event BUT and want to estimate its probability R.
From the law of large numbers P follows that:
Let us now estimate the practically possible error of the approximate equality (9.7). To do this, we use inequality (9.5) in the form:
For finding R on R it is necessary to solve inequality (9.8), for this it is necessary to square it and solve the corresponding quadratic equation. As a result, we get:
where 
For an approximate estimate R on R can be in the formula (9.8) R on the right, replace with R or in formulas (9.10), (9.11) consider that

Then we get:
Let in P= 400 experiments received frequency value R= 0.25, then at the confidence level y = 0.95 we find:
But what if we need to know the probability more accurately, with an error of, say, no more than 0.01? To do this, you need to increase the number of experiments.
Assuming in formula (9.12) the probability R= 0.25, we equate the error value given value 0.01 and get the equation for P:

Solving this equation, we get n~ 7500.
Let us now consider one more question: can the deviation of frequency from probability obtained in experiments be explained by random causes, or does this deviation show that the probability is not what we assumed it to be? In other words, experience confirms the accepted statistical hypothesis or, on the contrary, requires it to be rejected?
Let, for example, tossing a coin P= 800 times, we get the crest frequency R= 0.52. We suspected that the coin was not symmetrical. Is this suspicion justified? To answer this question, we will proceed from the assumption that the coin is symmetrical (p = 0.5). Let's find the confidence interval (with the confidence probability at= 0.95) for the frequency of appearance of the coat of arms. If the value obtained in the experiment R= 0.52 fits into this interval - everything is normal, the accepted hypothesis about the symmetry of the coin does not contradict the experimental data. Formula (9.12) for R= 0.5 gives an interval of 0.5 ± 0.035; received value p = 0.52 fits into this interval, which means that the coin will have to be “cleared” of suspicions of asymmetry.
Similar methods are used to judge whether various deviations from the mathematical expectation observed in random phenomena are random or "significant". For example, was there an accidental underweight in several samples of packaged goods, or does it indicate a systematic deception of buyers? Accidentally increased the percentage of recoveries in patients who used new drug, or is it related to the action of the drug?
The normal law plays a particularly important role in probability theory and its practical applications. We have already seen above that a random variable - the number of occurrences of some event in the Bernoulli scheme - when P-» °° reduces to the normal law. However, there is a much more general result.
Central limit theorem. The sum of a large number of independent (or weakly dependent) random variables comparable with each other in the order of their dispersions is distributed according to the normal law, regardless of what the distribution laws of the terms were. The above statement is a rough qualitative formulation of the central limit theory. This theorem has many forms that differ from each other in the conditions that random variables must satisfy in order for their sum to “normalize” with an increase in the number of terms.
The density of the normal distribution Dx) is expressed by the formula:
where a - expected value random variable X s= V7) is its standard deviation.
To calculate the probability of x falling within the interval (x 1? x 2), the integral is used:
Since integral (9.14) at density (9.13) cannot be expressed in terms of elementary functions(“not taken”), then to calculate (9.14) they use the tables of the integral distribution function of the standard normal distribution, when a = 0, a = 1 (such tables are available in any textbook on probability theory):
Probability (9.14) using equation (10.15) is expressed by the formula:
Example. Find the probability that the random variable x, having a normal distribution with parameters a, a, deviate from its mathematical expectation modulo no more than 3a.
Using formula (9.16) and the table of the distribution function of the normal law, we get:
Example. In each of the 700 independent experiences, an event BUT happens with constant probability R= 0.35. Find the probability that the event BUT will happen:
- 1) exactly 270 times;
- 2) less than 270 and more than 230 times;
- 3) more than 270 times.
Finding the mathematical expectation a = etc and standard deviation:
![]()
random variable - the number of occurrences of the event BUT:

Finding the centered and normalized value X:

According to the density tables of the normal distribution, we find f(x):
![]()

Let's find now R w (x,> 270) = P 700 (270 F(1.98) == 1 - 0.97615 = 0.02385.
A serious step in the study of the problems of large numbers was made in 1867 by P. L. Chebyshev. He considered a very general case, when nothing is required from independent random variables, except for the existence of mathematical expectations and variances.
Chebyshev's inequality. For an arbitrarily small positive number e, the following inequality holds:
Chebyshev's theorem. If a x x, x 2, ..., x n - pairwise independent random variables, each of which has a mathematical expectation E(Xj) = ci and dispersion D(x,) =), and the variances are uniformly bounded, i.e. 1,2 ..., then for an arbitrarily small positive number e the relation is fulfilled:
Consequence. If a a,= aio, -o 2 , i= 1,2 ..., then
A task. How many times must a coin be tossed so that with probability at least y - 0.997, could it be argued that the frequency of the coat of arms would be in the interval (0.499; 0.501)?
Suppose the coin is symmetrical, p - q - 0.5. We apply the Chebyshev theorem in formula (9.19) to the random variable X- the frequency of appearance of the coat of arms in P coin tossing. We have already shown above that X = X x + X 2 + ... +Х„, where X t - a random variable that takes the value 1 if the coat of arms fell out, and the value 0 if the tails fell out. So:
We write inequality (9.19) for an event opposite to the event indicated under the probability sign:

In our case, [e \u003d 0.001, cj 2 \u003d /? -p)] t is the number of coats of arms in P throwing. Substituting these quantities into the last inequality and taking into account that, according to the condition of the problem, the inequality must be satisfied, we obtain:

The given example illustrates the possibility of using Chebyshev's inequality for estimating the probabilities of certain deviations of random variables (as well as problems like this example related to the calculation of these probabilities). The advantage of Chebyshev's inequality is that it does not require knowledge of the laws of distributions of random variables. Of course, if such a law is known, then Chebyshev's inequality gives too rough estimates.
Consider the same example, but using the fact that coin tossing is a special case of the Bernoulli scheme. The number of successes (in the example - the number of coats of arms) obeys the binomial law, and with a large P this law can be represented by the integral theorem of Moivre - Laplace as a normal law with mathematical expectation a = pr = n? 0.5 and with standard deviation a = yfnpq- 25=0.5l/l. The random variable - the frequency of the coat of arms - has a mathematical expectation = 0.5 and a standard deviation

Then we have:

From the last inequality we get:

From the normal distribution tables we find:

We see that the normal approximation gives the number of coin tosses, which provides a given error in estimating the probability of the coat of arms, which is 37 times smaller than the estimate obtained using the Chebyshev inequality (but the Chebyshev inequality makes it possible to perform similar calculations even in the case when we do not have the information on the law of distribution of the random variable under study).
Let us now consider an applied problem solved with the help of formula (9.16).
Competition problem. Two competing railway companies each have one train running between Moscow and St. Petersburg. These trains are equipped in approximately the same way, they also depart and arrive at approximately the same time. Let's pretend that P= 1000 passengers independently and randomly choose a train for themselves, therefore, as a mathematical model for choosing a train by passengers, we use the Bernoulli scheme with P trials and chances of success R= 0.5. The company must decide how many seats to provide on the train, taking into account two mutually contradictory conditions: on the one hand, they don’t want to have empty seats, on the other hand, they don’t want to appear dissatisfied with the lack of seats (next time they will prefer competing firms). Of course, you can provide on the train P= 1000 seats, but then there will certainly be empty seats. The random variable - the number of passengers in the train - within the framework of the accepted mathematical model using the integral theory of Moivre - Laplace obeys the normal law with the mathematical expectation a = pr = n/2 and dispersion a 2 = npq = p/4 sequentially. The probability that the train will come to more than s passengers is determined by the ratio:

Set the risk level a, i.e. the probability that more than s passengers: 
From here: 
If a a- the risk root of the last equation, which is found in the tables of the distribution function of the normal law, we get: 
If, for example, P = 1000, a= 0.01 (this level of risk means that the number of places s will be sufficient in 99 cases out of 100), then x a ~ 2.33 and s= 537 places. Moreover, if both companies accept the same levels of risk a= 0.01, then the two trains will have a total of 1074 seats, 74 of which will be empty. Similarly, one can calculate that 514 places would be enough in 80% of all cases, and 549 places in 999 out of 1000 cases.
Similar considerations apply to other competitive service problems. For example, if t cinemas compete for the same P spectators, it should be accepted R= -. We get
that the number of seats s in the cinema should be determined by the ratio:

The total number of empty seats is equal to:

For a = 0,01, P= 1000 and t= 2, 3, 4 the values of this number are approximately equal to 74, 126, 147, respectively.
Let's consider one more example. Let the train be P - 100 wagons. The weight of each wagon is a random variable with mathematical expectation a - 65 tons and mean square expectation o = 9 tons. A locomotive can carry a train if its weight does not exceed 6600 tons; otherwise, you have to hook up the second locomotive. We need to find the probability that this will not be necessary.
weights of individual wagons:  having the same mathematical expectation a - 65 and the same variance d- o 2 \u003d 81. According to the rule of mathematical expectations: E(x) - 100 * 65 = 6500. According to the rule of addition of variances: D(x) \u003d 100 x 81 \u003d 8100. Taking the root, we find the standard deviation. In order for one locomotive to be able to pull a train, it is necessary that the weight of the train X turned out to be limiting, i.e., fell within the limits of the interval (0; 6600). The random variable x - the sum of 100 terms - can be considered normally distributed. By formula (9.16) we get:
having the same mathematical expectation a - 65 and the same variance d- o 2 \u003d 81. According to the rule of mathematical expectations: E(x) - 100 * 65 = 6500. According to the rule of addition of variances: D(x) \u003d 100 x 81 \u003d 8100. Taking the root, we find the standard deviation. In order for one locomotive to be able to pull a train, it is necessary that the weight of the train X turned out to be limiting, i.e., fell within the limits of the interval (0; 6600). The random variable x - the sum of 100 terms - can be considered normally distributed. By formula (9.16) we get:

It follows that the locomotive will "handle" the train with approximately 0.864 probability. Let us now reduce the number of cars in the train by two, i.e., take P= 98. Calculating now the probability that the locomotive will “handle” the train, we get a value of the order of 0.99, i.e., a practically certain event, although only two cars had to be removed for this.
So, if we are dealing with sums of a large number of random variables, then we can use the normal law. Naturally, this raises the question: how many random variables need to be added so that the distribution law of the sum is already “normalized”? It depends on what the laws of distribution of terms are. There are such intricate laws that normalization occurs only with a very large number of terms. But these laws are invented by mathematicians, while nature, as a rule, specifically does not arrange such troubles. Usually in practice, in order to be able to use the normal law, five or six terms are sufficient.
The speed with which the law of distribution of the sum of identically distributed random variables "normalizes" can be illustrated by the example of random variables with a uniform distribution on the interval (0, 1). The curve of such a distribution has the form of a rectangle, which is already unlike the normal law. Let's add two of these independent quantities- we get a random variable distributed according to the so-called Simpson's law, graphic image which looks like an isosceles triangle. It doesn't look like a normal law either, but it's better. And if you add three such uniformly distributed random variables, you get a curve consisting of three segments of parabolas, very similar to a normal curve. If you add six such random variables, you get a curve that does not differ from a normal one. This is the basis of the widely used method for obtaining a normally distributed random variable, while all modern computers are equipped with sensors of uniformly distributed (0, 1) random numbers.
The following method is recommended as one practical way to check this. We build a confidence interval for the frequency of an event with a level at= 0.997 according to the three sigma rule:

and if both its ends do not go beyond the segment (0, 1), then the normal law can be used. If any of the boundaries of the confidence interval is outside the segment (0, 1), then the normal law cannot be used. However, under certain conditions, the binomial law for the frequency of some random event, if it does not tend to the normal one, can tend to another law.
In many applications, the Bernoulli scheme is used as a mathematical model of a random experiment, in which the number of trials P great, random event quite rare, i.e. R = etc not small, but not large (fluctuates in the range of O -5 - 20). In this case, the following relation holds:
Formula (9.20) is called the Poisson approximation for the binomial law, since the probability distribution on its right side is called Poisson's law. The Poisson distribution is said to be a probability distribution for rare events, since it occurs when the limits are met: P -»°°, R-»0, but X = pr oo.
Example. Birthdays. What is the probability R t (k) that in a society of 500 people to people born on New Year's Day? If these 500 people are chosen at random, then the Bernoulli scheme can be applied with a probability of success P = 1/365. Then

Probability calculations for various to give the following values: RU = 0,3484...; R 2 = 0,2388...; R 3 = 0,1089...; P 4 = 0,0372...; R 5 = 0,0101...; R 6= 0.0023... Corresponding approximations by the Poisson formula for X= 500 1/365 = 1,37
give the following values: Ru = 0,3481...; R 2 = 0,2385...; Р b = 0,1089; R 4 = 0,0373...; P 5 = 0,0102...; P 6 = 0.0023... All errors are only in the fourth decimal place.
Let us give examples of situations where Poisson's law of rare events can be used.
At the telephone exchange, an incorrect connection is unlikely to occur. R, usually R~ 0.005. Then the Poisson formula allows you to find the probability of incorrect connections for a given total number connections n~ 1000 when X = pr =1000 0,005 = 5.
When baking buns, raisins are placed in the dough. It should be expected that due to stirring, the frequency of raisin rolls will approximately follow the Poisson distribution P n (k, X), where X- density of raisins in the dough.
A radioactive substance emits n-particles. The event that the number of d-particles reaching in the course of time t given area of space, takes a fixed value to, obeys Poisson's law.
The number of living cells with altered chromosomes under the influence of x-rays follows a Poisson distribution.
So, the laws of large numbers make it possible to solve the problem of mathematical statistics associated with estimating unknown probabilities of elementary outcomes of a random experiment. Thanks to this knowledge, we make the methods of probability theory practically meaningful and useful. The laws of large numbers also make it possible to solve the problem of obtaining information about unknown elementary probabilities in another form - the form of testing statistical hypotheses.
Let us consider in more detail the formulation and the probabilistic mechanism for solving problems of testing statistical hypotheses.
The words about large numbers refer to the number of tests - a large number of values of a random variable or the cumulative action of a large number of random variables are considered. The essence of this law is as follows: although it is impossible to predict what value a single random variable will take in a single experiment, however, the total result of the action of a large number of independent random variables loses its random character and can be predicted almost reliably (i.e. with high probability). For example, it is impossible to predict which side a coin will fall on. However, if you toss 2 tons of coins, then with great certainty it can be argued that the weight of the coins that fell with the coat of arms up is 1 ton.
First of all, the so-called Chebyshev inequality refers to the law of large numbers, which estimates in a separate test the probability of accepting a value by a random variable that deviates from the average value by no more than a given value.
Chebyshev's inequality. Let X is an arbitrary random variable, a=M(X) , a D(X) is its dispersion. Then
Example. The nominal (i.e. required) value of the diameter of the sleeve machined on the machine is 5mm, and the variance is no more 0.01 (this is the accuracy tolerance of the machine). Estimate the probability that in the manufacture of one bushing, the deviation of its diameter from the nominal will be less than 0.5mm .
Solution. Let r.v. X- the diameter of the manufactured bushing. By condition, its mathematical expectation is equal to the nominal diameter (if there is no systematic failure in setting up the machine): a=M(X)=5 , and the variance D(X)≤0.01. Applying the Chebyshev inequality for ε = 0.5, we get:
Thus, the probability of such a deviation is quite high, and therefore we can conclude that in the case of a single production of a part, the deviation of the diameter from the nominal one will almost certainly not exceed 0.5mm .
Basically, the standard deviation σ characterizes average deviation of a random variable from its center (i.e. from its mathematical expectation). Because it average deviation, then large deviations (emphasis on o) are possible during testing. How large deviations are practically possible? When studying normally distributed random variables, we derived the “three sigma” rule: a normally distributed random variable X in a single test practically does not deviate from its average further than 3σ, where σ= σ(X) is the standard deviation of r.v. X. We deduced such a rule from the fact that we obtained the inequality
 .
.
Let us now estimate the probability for arbitrary random variable X accept a value that differs from the mean by no more than three times the standard deviation. Applying the Chebyshev inequality for ε = 3σ and given that D(X)=σ 2 , we get:
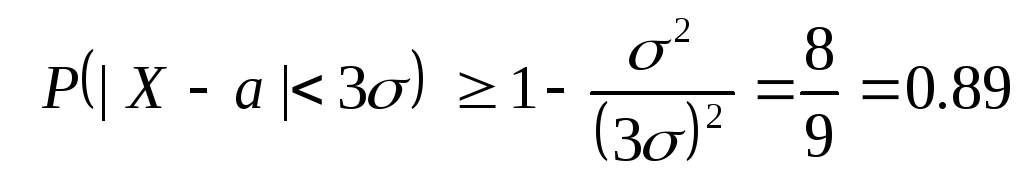 .
.
In this way, in general we can estimate the probability of a random variable deviating from its mean by no more than three standard deviations by the number 0.89 , while for a normal distribution it can be guaranteed with probability 0.997 .
Chebyshev's inequality can be generalized to a system of independent identically distributed random variables.
Generalized Chebyshev's inequality. If independent random variables X 1 , X 2 , … , X n M(X i )= a and dispersions D(X i )= D, then
At n=1 this inequality goes over into the Chebyshev inequality formulated above.
The Chebyshev inequality, having independent significance for solving the corresponding problems, is used to prove the so-called Chebyshev theorem. We first describe the essence of this theorem and then give its formal formulation.
Let X 1
, X 2
, … , X n– a large number of independent random variables with mathematical expectations M(X 1
)=a 1
, … , M(X n )=a n. Although each of them, as a result of the experiment, can take a value far from its average (i.e., mathematical expectation), however, a random variable  , equal to their arithmetic mean, with a high probability will take a value close to a fixed number
, equal to their arithmetic mean, with a high probability will take a value close to a fixed number  (this is the average of all mathematical expectations). This means the following. Let, as a result of the test, independent random variables X 1
, X 2
, … , X n(there are a lot of them!) have taken the values accordingly X 1
, X 2
, … , X n respectively. Then if these values themselves may turn out to be far from the average values of the corresponding random variables, their average value
(this is the average of all mathematical expectations). This means the following. Let, as a result of the test, independent random variables X 1
, X 2
, … , X n(there are a lot of them!) have taken the values accordingly X 1
, X 2
, … , X n respectively. Then if these values themselves may turn out to be far from the average values of the corresponding random variables, their average value  is likely to be close to
is likely to be close to  . Thus, the arithmetic mean of a large number of random variables already loses its random character and can be predicted with great accuracy. This can be explained by the fact that random deviations of the values X i from a i can be of different signs, and therefore in total these deviations are compensated with a high probability.
. Thus, the arithmetic mean of a large number of random variables already loses its random character and can be predicted with great accuracy. This can be explained by the fact that random deviations of the values X i from a i can be of different signs, and therefore in total these deviations are compensated with a high probability.
Terema Chebysheva (law of large numbers in the form of Chebyshev). Let X 1 , X 2 , … , X n … is a sequence of pairwise independent random variables whose variances are limited to the same number. Then, no matter how small the number ε we take, the probability of inequality
will be arbitrarily close to unity if the number n random variables to take large enough. Formally, this means that under the conditions of the theorem
This type of convergence is called convergence in probability and is denoted by:
Thus, the Chebyshev theorem says that if there are a sufficiently large number of independent random variables, then their arithmetic mean in a single test will almost certainly take a value close to the average of their mathematical expectations.
Most often, the Chebyshev theorem is applied in a situation where random variables X 1 , X 2 , … , X n … have the same distribution (i.e. the same distribution law or the same probability density). In fact, this is just a large number of instances of the same random variable.
Consequence(of the generalized Chebyshev inequality). If independent random variables X 1 , X 2 , … , X n … have the same distribution with mathematical expectations M(X i )= a and dispersions D(X i )= D, then
 , i.e.
, i.e.  .
.
The proof follows from the generalized Chebyshev inequality by passing to the limit as n→∞ .
We note once again that the equalities written above do not guarantee that the value of the quantity  tends to a at n→∞. This value is still a random variable, and its individual values can be quite far from a. But the probability of such (far from a) values with increasing n tends to 0.
tends to a at n→∞. This value is still a random variable, and its individual values can be quite far from a. But the probability of such (far from a) values with increasing n tends to 0.
Comment. The conclusion of the corollary is obviously also valid in the more general case when the independent random variables X 1 , X 2 , … , X n … have a different distribution, but the same mathematical expectations (equal a) and the variances limited in the aggregate. This makes it possible to predict the accuracy of measuring a certain quantity, even if these measurements are made by different instruments.
Let us consider in more detail the application of this corollary to the measurement of quantities. Let's use some device n measurements of the same quantity, the true value of which is a and we don't know. The results of such measurements X 1
, X 2
, … , X n may differ significantly from each other (and from the true value a) due to various random factors (pressure drops, temperatures, random vibration, etc.). Consider the r.v. X- instrument reading for a single measurement of a quantity, as well as a set of r.v. X 1
, X 2
, … , X n- instrument reading at the first, second, ..., last measurement. Thus, each of the quantities X 1
, X 2
, … , X n
there is just one of the instances of the r.v. X, and therefore they all have the same distribution as the r.v. X. Since the measurement results are independent of each other, the r.v. X 1
, X 2
, … , X n can be considered independent. If the device does not give a systematic error (for example, zero is not “knocked down” on the scale, the spring is not stretched, etc.), then we can assume that the mathematical expectation M(X) = a, and therefore M(X 1
) = ... = M(X n ) = a. Thus, the conditions of the above corollary are satisfied, and therefore, as an approximate value of the quantity a we can take the "implementation" of a random variable  in our experiment (consisting of a series of n measurements), i.e.
in our experiment (consisting of a series of n measurements), i.e.
 .
.
With a large number of measurements, the good accuracy of the calculation using this formula is practically reliable. This is the rationale for the practical principle that with a large number of measurements, their arithmetic mean practically does not differ much from the true value of the measured quantity.
The “sampling” method, which is widely used in mathematical statistics, is based on the law of large numbers, which allows obtaining its objective characteristics with acceptable accuracy from a relatively small sample of values of a random variable. But this will be discussed in the next section.
Example. On the measuring device, which does not make systematic distortions, a certain value is measured a once (received value X 1
), and then another 99 times (obtained values X 2
, … , X 100
). For the true value of measurement a first take the result of the first measurement  , and then the arithmetic mean of all measurements
, and then the arithmetic mean of all measurements  . The measurement accuracy of the device is such that the standard deviation of the measurement σ is not more than 1 (because the dispersion D=σ
2
also does not exceed 1). For each of the measurement methods, estimate the probability that the measurement error does not exceed 2.
. The measurement accuracy of the device is such that the standard deviation of the measurement σ is not more than 1 (because the dispersion D=σ
2
also does not exceed 1). For each of the measurement methods, estimate the probability that the measurement error does not exceed 2.
Solution. Let r.v. X- instrument reading for a single measurement. Then by condition M(X)=a. To answer the questions posed, we apply the generalized Chebyshev inequality

for ε =2
first for n=1
and then for n=100
. In the first case, we get  , and in the second. Thus, the second case practically guarantees the given measurement accuracy, while the first one leaves serious doubts in this sense.
, and in the second. Thus, the second case practically guarantees the given measurement accuracy, while the first one leaves serious doubts in this sense.
Let us apply the above statements to the random variables that arise in the Bernoulli scheme. Let us recall the essence of this scheme. Let it be produced n independent tests, in each of which some event BUT can appear with the same probability R, a q=1–r(by meaning, this is the probability of the opposite event - not the occurrence of an event BUT) . Let's spend some number n such tests. Consider random variables: X 1 – number of occurrences of the event BUT in 1 th test, ..., X n– number of occurrences of the event BUT in n th test. All introduced r.v. can take values 0 or 1 (event BUT may appear in the test or not), and the value 1 conditionally accepted in each trial with a probability p(probability of occurrence of an event BUT in each test), and the value 0 with probability q= 1 – p. Therefore, these quantities have the same distribution laws:
|
X 1 | ||
|
X n | ||
Therefore, the average values of these quantities and their dispersions are also the same: M(X 1 )=0 ∙ q+1 ∙ p= p, …, M(X n )= p ; D(X 1 )=(0 2 ∙ q+1 2 ∙ p)− p 2 = p∙(1− p)= p ∙ q, … , D(X n )= p ∙ q . Substituting these values into the generalized Chebyshev inequality, we obtain
 .
.
It is clear that the r.v. X=X 1 +…+X n is the number of occurrences of the event BUT in all n trials (as they say - "the number of successes" in n tests). Let in the n test event BUT appeared in k of them. Then the previous inequality can be written as
 .
.
But the magnitude  , equal to the ratio of the number of occurrences of the event BUT in n independent trials, to the total number of trials, previously called the relative event rate BUT in n tests. Therefore, there is an inequality
, equal to the ratio of the number of occurrences of the event BUT in n independent trials, to the total number of trials, previously called the relative event rate BUT in n tests. Therefore, there is an inequality
 .
.
Passing now to the limit at n→∞, we get  , i.e.
, i.e.  (according to probability). This is the content of the law of large numbers in the form of Bernoulli. It follows from this that for a sufficiently large number of trials n arbitrarily small deviations of the relative frequency
(according to probability). This is the content of the law of large numbers in the form of Bernoulli. It follows from this that for a sufficiently large number of trials n arbitrarily small deviations of the relative frequency  events from its probability R are almost certain events, and large deviations are almost impossible. The resulting conclusion about such stability of relative frequencies (which we previously referred to as experimental fact) justifies the previously introduced statistical definition of the probability of an event as a number around which the relative frequency of an event fluctuates.
events from its probability R are almost certain events, and large deviations are almost impossible. The resulting conclusion about such stability of relative frequencies (which we previously referred to as experimental fact) justifies the previously introduced statistical definition of the probability of an event as a number around which the relative frequency of an event fluctuates.
Considering that the expression p∙
q=
p∙(1−
p)=
p−
p 2
does not exceed on the change interval  (it is easy to verify this by finding the minimum of this function on this segment), from the above inequality
(it is easy to verify this by finding the minimum of this function on this segment), from the above inequality  easy to get that
easy to get that
 ,
,
which is used in solving the corresponding problems (one of them will be given below).
Example. The coin was flipped 1000 times. Estimate the probability that the deviation of the relative frequency of the appearance of the coat of arms from its probability will be less than 0.1.
Solution. Applying the inequality  at p=
q=1/2
,
n=1000
,
ε=0.1, we get .
at p=
q=1/2
,
n=1000
,
ε=0.1, we get .
Example. Estimate the probability that, under the conditions of the previous example, the number k of the dropped coats of arms will be in the range of 400 before 600 .
Solution. Condition 400<
k<600
means that 400/1000<
k/
n<600/1000
, i.e. 0.4<
W n (A)<0.6
or  . As we have just seen from the previous example, the probability of such an event is at least 0.975
.
. As we have just seen from the previous example, the probability of such an event is at least 0.975
.
Example. To calculate the probability of some event BUT 1000 experiments were carried out, in which the event BUT appeared 300 times. Estimate the probability that the relative frequency (equal to 300/1000=0.3) is different from the true probability R no further than 0.1 .
Solution. Applying the above inequality  for n=1000, ε=0.1 , we get .
for n=1000, ε=0.1 , we get .
The practice of studying random phenomena shows that although the results of individual observations, even those carried out under the same conditions, can differ greatly, at the same time, the average results for a sufficiently large number of observations are stable and weakly depend on the results of individual observations.
The theoretical justification for this remarkable property of random phenomena is law of large numbers. The name "law of large numbers" combines a group of theorems that establish the stability of the average results of a large number of random phenomena and explain the reason for this stability.
The simplest form of the law of large numbers, and historically the first theorem of this section is Bernoulli's theorem stating that if the probability of an event is the same in all trials, then with an increase in the number of trials, the frequency of the event tends to the probability of the event and ceases to be random.
Poisson's theorem states that the frequency of an event in a series of independent trials tends to the arithmetic mean of its probabilities and ceases to be random.
Limit theorems of probability theory, theorems Moivre-Laplace explain the nature of the stability of the frequency of occurrence of an event. This nature consists in the fact that the limiting distribution of the number of occurrences of an event with an unlimited increase in the number of trials (if the probability of an event in all trials is the same) is normal distribution.
The central limit theorem explains the widespread use normal law distribution. The theorem states that whenever a random variable is formed as a result of adding a large number of independent random variables with finite variances, the distribution law of this random variable turns out to be practically normal by law.
The theorem below, titled " Law of Large Numbers" asserts that under certain, rather general, conditions, with an increase in the number of random variables, their arithmetic mean tends to the arithmetic mean of mathematical expectations and ceases to be random.
Lyapunov's theorem explains the widespread normal law distribution and explains the mechanism of its formation. The theorem allows us to assert that whenever a random variable is formed as a result of adding a large number of independent random variables, the variances of which are small compared to the variance of the sum, the distribution law of this random variable turns out to be practically normal by law. And since random variables are always generated by an infinite number of causes, and most often none of them has a variance comparable to the variance of the random variable itself, most of the random variables encountered in practice are subject to the normal distribution law.
The qualitative and quantitative statements of the law of large numbers are based on Chebyshev's inequality. It defines the upper bound on the probability that the deviation of the value of a random variable from its mathematical expectation is greater than some given number. Remarkably, the Chebyshev inequality gives an estimate of the probability of the event for a random variable whose distribution is unknown, only its mathematical expectation and variance are known.
Chebyshev's inequality. If a random variable x has a variance, then for any e > 0 the inequality ![]() , where M x and D x - mathematical expectation and variance of the random variable x .
, where M x and D x - mathematical expectation and variance of the random variable x .
Bernoulli's theorem. Let m n be the number of successes in n Bernoulli trials and p be the probability of success in a single trial. Then for any e > 0 we have ![]() .
.
Central limit theorem. If random variables x 1 , x 2 , …, x n , … are pairwise independent, equally distributed and have finite variance, then at n ® uniformly in x (- ,)





